- About
- People
- Research
- Engagement
- Data
- Technical
- Search
Architecture
Vision
The vision of pSCANNER is to provide a scalable and flexible distributed infrastructure for collaborative comparative effectiveness research, while engaging patients and clinicians regarding network governance and use. pSCANNER will be used for conducting multiple studies within the same computer network, where each study might focus on different clinical domains, have varying data needs and data models, and might have different data sharing policies, and with different combinations of sites participating in each study. The network will scale to accommodate the volume and heterogeneity of studies, data, users, and policies.
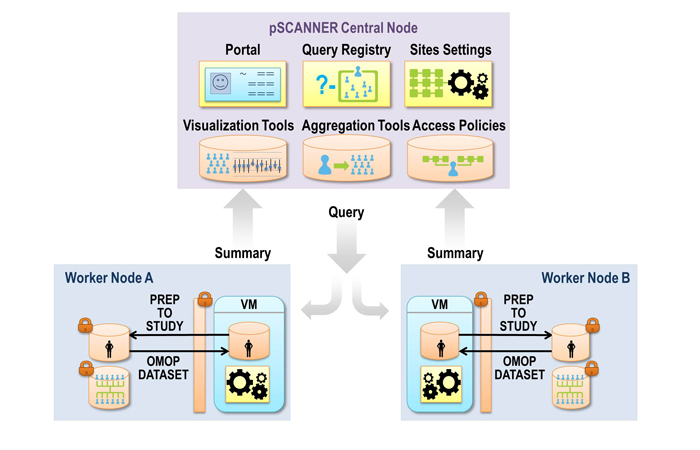
The figure above shows the conceptual architecture of pSCANNER. pSCANNER will expand on the distributed architecture developed in SCANNER. SCANNER’s infrastructure was designed based on requirements from major stakeholders in stewardship and use of clinical data for research: patients, researchers, and administrators. Comparative effectiveness researchers will access the resources at study sites through the pSCANNER portal. The portal will expose applications that can request resources from various sites participating in a study, and integrate the resources to present to the researcher. For example, an application will allow the researcher to compose a query for de-identified data from each site, integrate the results into one data set, and display the results.
SCANNER is comprised of a set of SSL-encrypted Web Services that allow a user to perform distributed statistical analysis on data hosted on remote sites. Multiple statistical analysis methods are supported via a plug-in architecture, and a defined set of input and output formats provide a consistent I/O interface for each computational plug-in. The network integrates instances of the pSCANNER Central and Worker nodes. In order to submit work to the network, a user first authenticates his or her identity to the Portal that upon success presents a web-based graphical user interface to the user. The Portal interface presents a set of selection controls (based on information stored in the Registry) about what datasets, computational algorithms, and remote nodes are available for the user to execute a query against. Once a user has selected the criterion for a query and initiates the execution of the query, the Portal then sends the query request to the proper remote Worker nodes, where a number of computational plug-ins with statistical methods are deployed. Depending on what analysis algorithm was selected, this query process may be iterated multiple times in order to optimize the statistical result. Once the distributed query completes, the results are collated by the corresponding algorithm’s computational plug-in, and the end results are returned as a single output payload back to the Portal, where it is finally displayed to the user.
The Worker node exposes resources provided by each site to the network. Each participating institution hosts its own pSCANNER Worker node (Linux-based Virtual Machine containing pSCANNER software provided to each institution), which includes resources such as databases and data sets, as well as, computational services. The types of computational services available are data analysis services, and will include the Observational Cohort Event Analysis and Notification System (OCEANS) and Grid Binary LOgistic REgression (GLORE) tools.
While the architecture described above does not require a specific data model, many of the resources and tools implemented in pSCANNER will use the OMOP version 5.1 common data model. Depending on the data resources and tools available at each site, the respective pSCANNER Worker nodes will contain a data transformation service that can convert the OMOP format data to formats needed by analytical services.
Data Governance
The access control to data in pSCANNER will be delegated to the site that is providing the data. Sites implement their data access policies using the policy enforcement modules. Access policies will be specified as credential expressions that themselves specify the roles of the users accessing a resource, and how the users are authenticated. For example, a credential expression could state that access to a data set is limited to study investigators as specified in an Institutional Review Board (IRB) approvals database, and the user must belong to one of the study sites and be authenticated by that site’s enterprise authentication services. Beyond access control, we will investigate means for sites to have other trust services for each resource, e.g., records retention.
Copyright © 2017 pSCANNER | ![]()